코드:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
|
from tkinter import *
import openpyxl
from datetime import date
import pandas as pd
import xlrd
import bs4
import urllib.request
import requests
from bs4 import BeautifulSoup
today = date.today()
balance = 10000000
balance_2 = 10000000
get_wb = xlrd.open_workbook(get_loc)
get_sheet = get_wb.sheet_by_index(0)
write_loc = ("E:\\3_2\\python\\Tkinter\\stock_today\\" + str(today) + ".xlsx")
write_wb = openpyxl.Workbook()
write_sheet = write_wb.active
get_loc_2 = ("E:\\3_2\\python\\Tkinter\\company_list.xlsx")
df_2 = pd.read_excel(get_loc_2, sheetname=0, converters={'종목코드':str})
price_arr = []
def get_bs_obj(company):
result = requests.get(url)
bs_obj = BeautifulSoup(result.content, "html.parser")
return bs_obj
def get_price(company):
bs_obj = get_bs_obj(company)
return blind_now.text
def get_up_10():
left_balance = balance
for i in range(1, 11):
left_balance -= int(get_sheet.cell_value(i, 1)) * 10
write_sheet['C2'] = left_balance
show_balance.configure(text="balance = " + str(left_balance))
return
def get_rate_down_10():
left_balance = balance
for i in range(309, 319):
left_balance -= int(get_sheet.cell_value(i, 1)) * 10
write_sheet['C3'] = left_balance
show_balance_2.configure(text="balance = " + str(left_balance))
return
def sell_up_10():
df = pd.read_excel(write_loc, sheetname=0)
company = df['company'].tolist()
for j in range(0, 10):
if company[j] == df_2['회사명'][i]:
company[j] = df_2['종목코드'][i]
for i in range(0, 10):
left_balance += int(get_price(company[i]).replace(",", "")) * 10
show_balance.configure(text="balance = " + str(left_balance))
return
def sell_rate_down_10():
df = pd.read_excel(write_loc, sheetname=0, )
company = df['company'].tolist()
for j in range(10, 20):
if company[j] == df_2['회사명'][i]:
company[j] = df_2['종목코드'][i]
print(company)
for i in range(10, 20):
left_balance += int(get_price(company[i]).replace(",", "")) * 10
show_balance_2.configure(text="balance = " + str(left_balance))
return
root = Tk()
root.title("stock program")
root.geometry("250x250")
show_today = Label(root, text = today)
up_10 = Button(root, text="buy up 10", command=get_up_10)
rate_down_10 = Button(root, text="buy rate down 10", command=get_rate_down_10)
show_balance = Label(root, text="balance = " + str(balance))
show_balance_2 = Label(root, text="balance = " + str(balance))
sell_up_10 = Button(root, text="sell up 10", command=sell_up_10)
sell_rate_down_10 = Button(root, text="sell rate down 10", command=sell_rate_down_10)
root.mainloop()
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
실행결과:
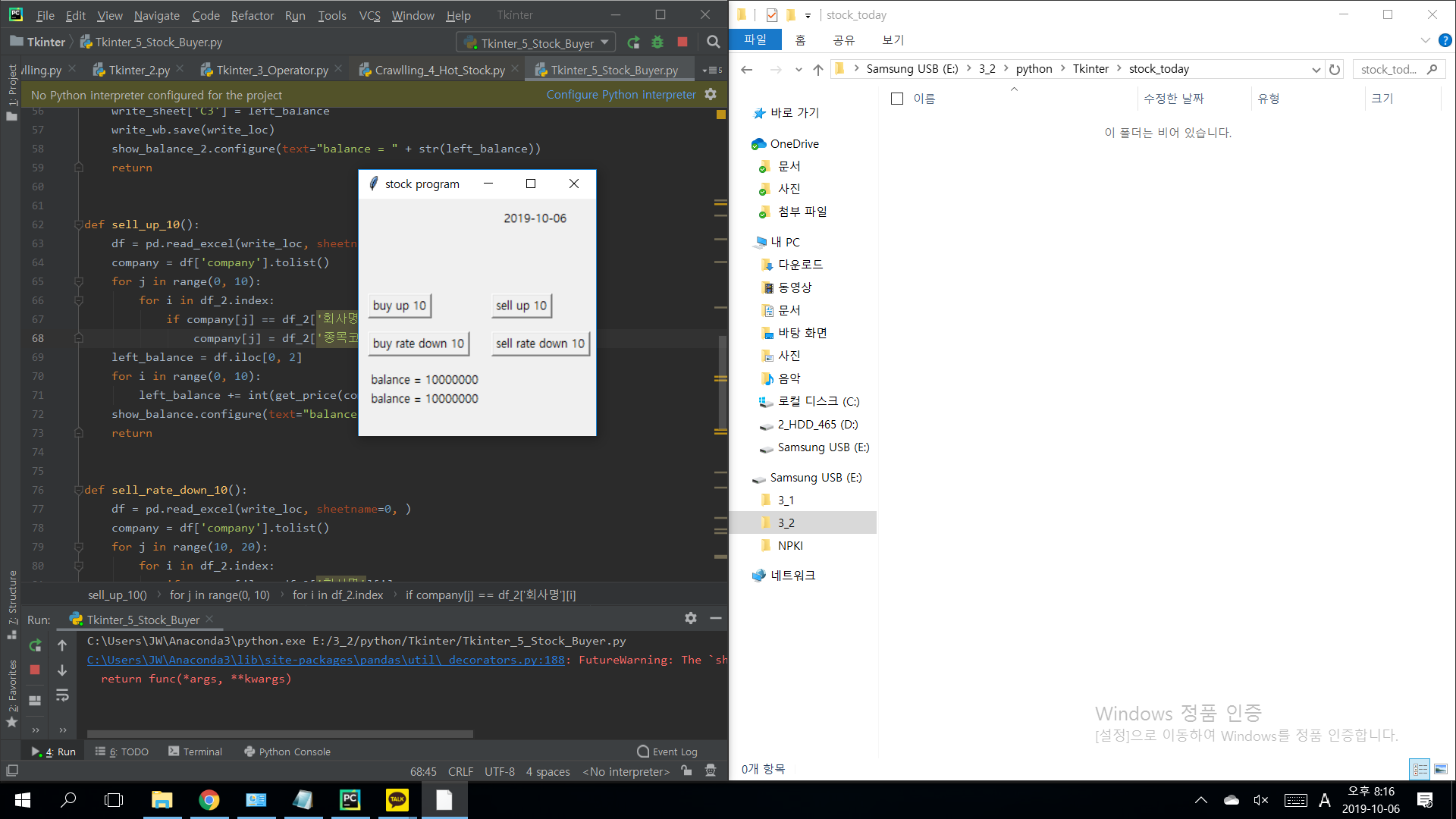
주식을 사기 전 각각 천만원의 계좌(balance)의 잔액이 있다.
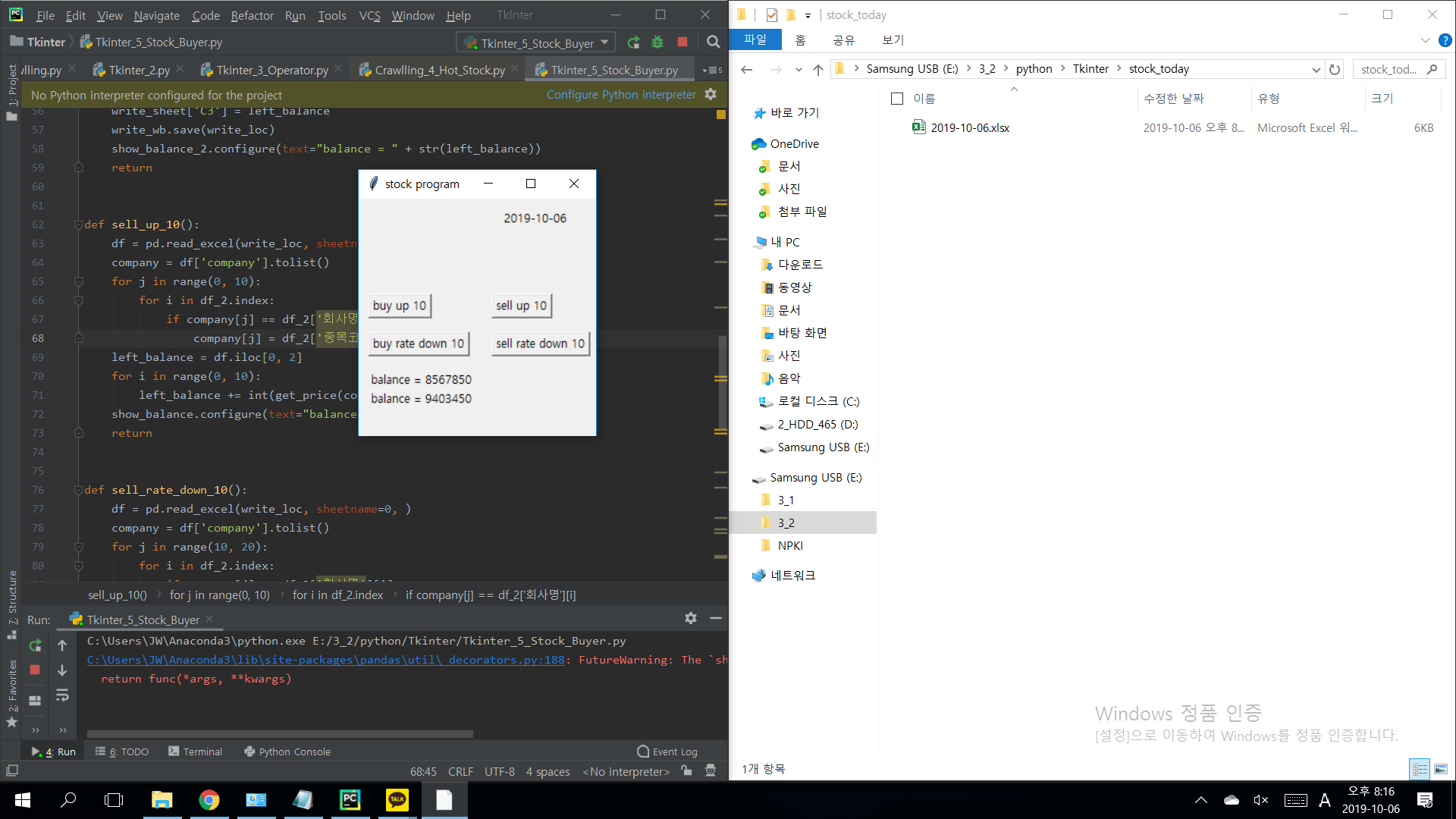
엑셀파일이 생성,

산 주식들의 회사명과 주가, 남은 계좌의 잔액이 입력되어있다.
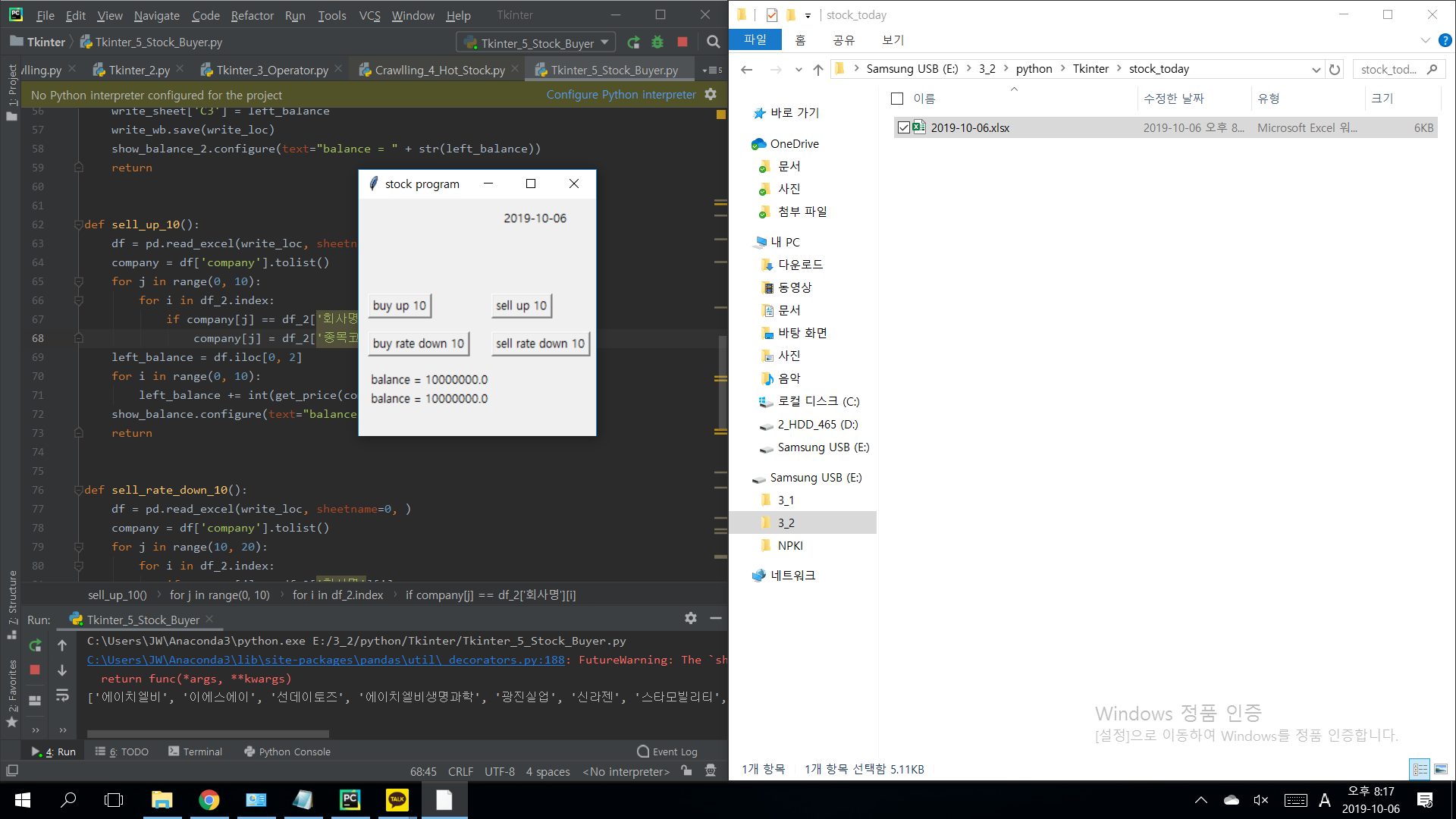
주식을 팔고 난 뒤의 계좌의 잔액을 확인할 수 있다. (포스팅 날짜는 주말이라 주가 변동이 없음)
설명:
get_loc = ("E:\\3_2\\python\\Tkinter\\stock_data\\" + str(today) + "_morning.xlsx")
get_wb = xlrd.open_workbook(get_loc)
get_sheet = get_wb.sheet_by_index(0)
xlrd라이브러릴 이용해서 해당 디렉토리의 엑셀파일을 가져오는 모습.
write_loc = ("E:\\3_2\\python\\Tkinter\\stock_today\\" + str(today) + ".xlsx")
write_wb = openpyxl.Workbook()
write_sheet = write_wb.active
write_sheet.append(["company", "price", "balance"])
상승주를 가져와서 엑셀파일에 저장. 아래 포스팅 참고.
Python,crawling, bs4, openpyxl, datetime, string, 상승주 가져오기
Python,crawling, bs4, openpyxl, datetime, string, 상승주 가져오기
코드: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import bs4 import urllib.reque..
coding-0830.tistory.com
df_2 = pd.read_excel(get_loc_2, sheetname=0, converters={'종목코드':str})
작성하 엑셀파일을 다시 ead_excel()로 읽는다. converters={'종목코드':str}를 한 이유는 0으로 시작하는 종목코드를 그대로 가져오면 앞에 0이 사라지기 때문.
def get_bs_obj(company):
url = "https://finance.naver.com/item/main.nhn?code=" + company
result = requests.get(url)
bs_obj = BeautifulSoup(result.content, "html.parser")
return bs_obj
def get_price(company):
bs_obj = get_bs_obj(company)
no_today = bs_obj.find("p", {"class": "no_today"})
blind_now = no_today.find("span", {"class": "blind"})
return blind_now.text
주가를 가져오는 함수, 기본적인 크롤링 방법, 아래 포스팅 참고
Python,crawling, bs4,인기검색어 가져오기
Python,crawling, bs4,인기검색어 가져오기
코드 : 1 2 3 4 5 6 7 8 9 import bs4 import urllib.request url = "http://naver.com" html = urllib.request.urlopen(url) bsobj = bs4.BeautifulSoup(html, "html.parser") realtime_hotkeyword = bsobj.find_..
coding-0830.tistory.com
def get_up_10():
left_balance = balance
for i in range(1, 11):
price_arr.append(get_sheet.cell_value(i, 1))
left_balance -= int(get_sheet.cell_value(i, 1)) * 10
write_sheet.append([get_sheet.cell_value(i, 0), get_sheet.cell_value(i, 1)])
write_sheet['C2'] = left_balance
show_balance.configure(text="balance = " + str(left_balance))
return
위에 따로 올린 상승주 가져오기 포스팅 코드를 이용해서 미리 다운받은 엑셀파일에서 상위 열개의 주가를 가져와 각10씩 사서 balance에서 빼는 모습. 그 balance는 새로 작성하는 엑셀파일의 C2자리에 넣는다.
def sell_up_10():
df = pd.read_excel(write_loc, sheetname=0)
company = df['company'].tolist()
for j in range(0, 10):
for i in df_2.index:
if company[j] == df_2['회사명'][i]:
company[j] = df_2['종목코드'][i]
left_balance = df.iloc[0, 2]
for i in range(0, 10):
left_balance += int(get_price(company[i]).replace(",", "")) * 10
show_balance.configure(text="balance = " + str(left_balance))
return
다시 되파는 코드, 상당히 골치 아팠다. 아침에 검색할 때와 장 마감후 검색하는 급등주는 서로 다르기 때문에 아침에 검색해서 샀던 주식을 따로 일일이 검색하여 가격을 받아와야하기 때문.
일단 미리 다운받았던 상장주식의 정보가 모두 들어있는 엑셀파일에 있는 회사명과 내가 산 주식의 회사명이 일치 한다면 해당 회사명을 종목코드로 바꿔주는 작업을 한 뒤, get_price()를 이용하여 주가를 가져온다.
이 때 주가는 86,000 처럼 중간에 콤마가 붙어있기 때문에 replace()함수를 이용하여 콤마를 없애준다.
그 후 다시 10주씩 판다는 가정하에, 잔액에 더해준다. 그리고 라벨을 업데이트된 잔액으로 바꾼다. 이는 아래 포스팅 참고.
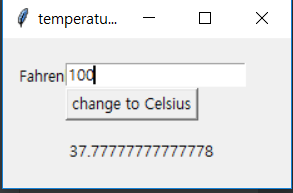
Python, Tkinter, 화씨에서 섭씨로 바꾸기
코드: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from tkinter import* #function which actions when the button is pushed def convert(): f = float(ent.get()) tmp = float(5 *..
coding-0830.tistory.com
이 하 코드는 기본적인 Tkinter라이브러리 사용방법이니 바로 위 포스팅 다시 참고.
'Python > Tkinter' 카테고리의 다른 글
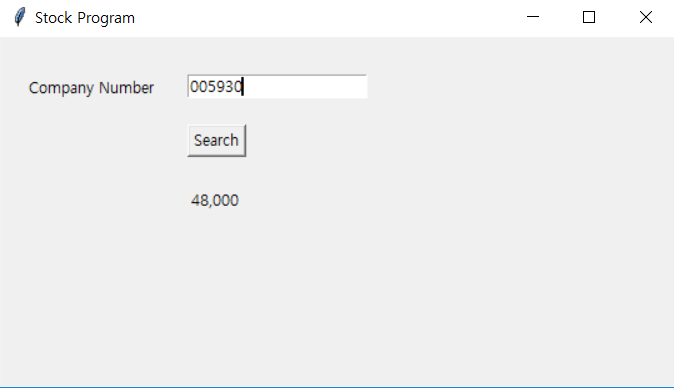
| Python, Tkinter, 현재 주가 가져오기 (0) | 2019.10.04 |
|---|---|
| Python, Tkinter, 화씨에서 섭씨로 바꾸기 (0) | 2019.10.04 |