코드 :
|
1
2
3
4
5
6
7
8
9
|
import bs4
import urllib.request
url = "http://naver.com"
html = urllib.request.urlopen(url)
bsobj = bs4.BeautifulSoup(html, "html.parser")
realtime_hotkeyword = bsobj.find_all("span", {"class":"ah_k"})
for keyword in realtime_hotkeyword:
print(keyword.text)
|
cs |
실행결과 :
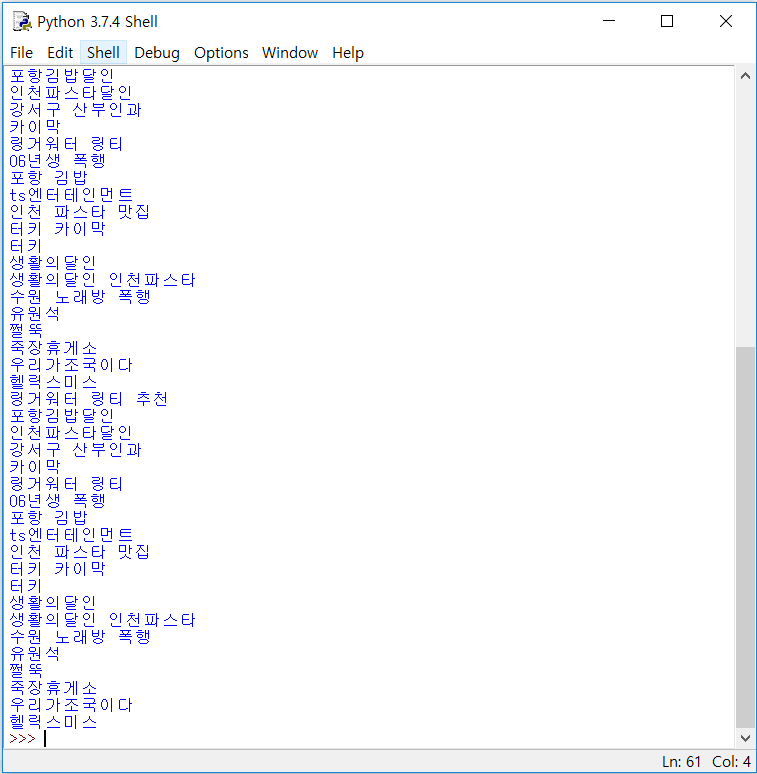
설명 :
import bs4
import urllib.request
bs4와 request모듈을 사용한다.
url = "http://naver.com"
html = urllib.request.urlopen(url)
urllib.request.urlopen()함수를 이용하여 url을 html이라는 변수에 저장했다.
bsobj = bs4.BeautifulSoup(html, "html.parser")
bs4.BeautifulSoup(매개변수, "html.parser") 함수를 통하여 파싱을 하고 bsobj라는 변수에 저장했다. 현재에는 해당 페이지의 모든 html문서가 저장되어있는 상황. print(bsobj)로 확인가능.
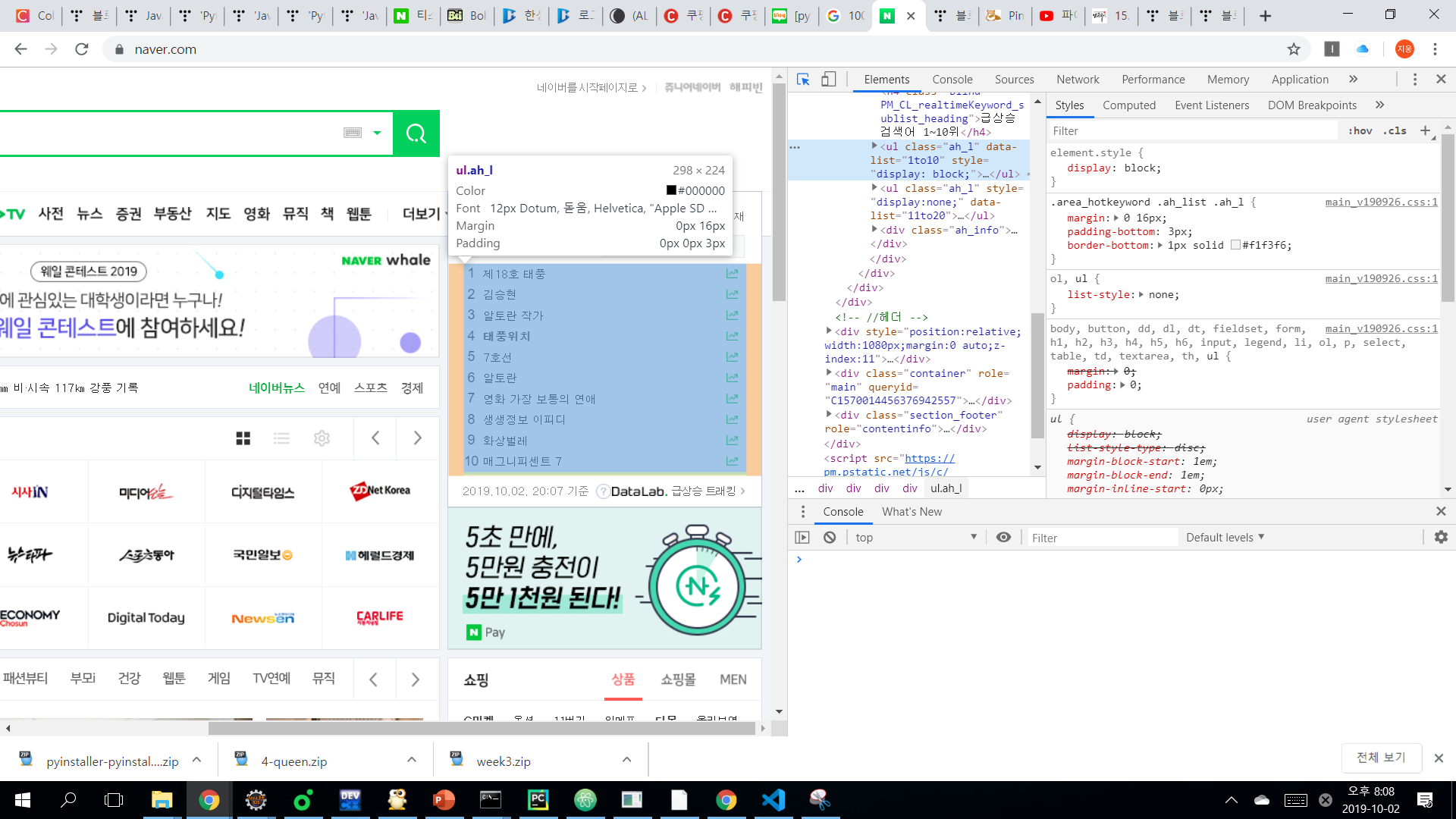
realtime_hotkeyword = bsobj.find_all("span", {"class":"ah_k"})
인기검색어에 해당하는 곳을 찾아보면 span태그안에 class 이름이 정해져있는 것을 알 수 있다.bsobj.find_all()함수를 이용하여 인기검색어들을 realtime_hotkeyword이라는 변수에 저장.
for keyword in realtime_hotkeyword:
print(keyword.text)
for문을 이용하여 모두 출력.
'Python > Crawling' 카테고리의 다른 글
| Python,crawling, bs4, openpyxl, datetime, string, 상승주 가져오기 (0) | 2019.10.06 |
|---|---|
| Python,crawling, bs4,pandas,주식 엑셀로 가져오기 (0) | 2019.10.02 |
| Python,crawling, selenium 로그인하기 (0) | 2019.10.02 |